| benchmarks | ||
| documents | ||
| src/models | ||
| tests | ||
| .gitignore | ||
| create_image.py | ||
| poetry.lock | ||
| pyproject.toml | ||
| pytest.ini | ||
| README.md | ||
Mantel Group Technical Challenge
This repository contains a productionised version (including testing and benchmarking) of the Kohonen Self Organising Map model implemented in the problem specification. Please let me know if there are any issues running the code.
Setting up this repository
Firstly, due to time constraints, there are components of this codebase that are not abstracted in such a way that they are conducive to collaborative work. There are certain hardcoded elemtns - particularly in the testing and benchmarking modules. I have chosen what I believe to be reasonable defaults for running testing and benchmarking on an average machine.
Setup environment
Python Poetry is used as a package manager for this project. It can be isntalled by following the documentation.
Once Poetry is installed, run poetry install to create a virtual environment with the necessary dependencies.
Running tests
Run tests using pytest tests. Tests are contained in ./tests.
Running benchmarking
Run benchmarks using pytest benchmarks. Running benchmarks will create MLFlow experiments that can be inspected in the MLFlow dashboard that will be served at http://127.0.0.1:5000/ after running mlflow ui. Benchmarks are contained in ./benchmarks.
Mantel Code Assessment
Whilst the tests, benchmarking and organisation of my Kohonen Network implementation should intimate a more production-ready codebase, I will highlight some key improvements I have made to the implementation.
Using ASCII variables for variable names
The components of a Kohonen Network can all be expressed using mathematical notation, so it seems logical to use these same mathematical symbols in one's code. However, I would suggest two key reasons to Sam why using non-ASCII characters are usually undesirbale.
- Developers reading and maintaining the code might not be familiar with the mathematical formulae and therefore, would be unable to make sense of semantic sense of such variables.
- Non-ASCII characters are not typically found on standard keyboard, making typing such variable names inconvenient
Thus, I always use ASCII characters and make a careful effort to utilise descriptive and unambiguous variable names rather than short and forgettable variable names.
Packaging
Sam's implementation expects to be executed as a Python module due to the if __name__ == '__main__': block. Whilst this is okay during first-pass development, I would ask Sam how he would advise others to use his module in this way, and it would soon come to light that there is no CLI argument parsing or other method by which someone could use the module on their own data.
I would suggest that Sam package his code in a way similar to how I have done - where I've created a models package that includes a kohonen_network.py module and directly exposes the train_kohon_network, allowing for anyone to easily from models import train_kohon_network to train their own model on their own data.
Modularisation
Sam's train function is dense and does not make use of any helper functions. For a complex algorithm such as training a Kohonen Network, there are several downsides to having a monolothic fucntion:
- Reduced readability
- More difficult to make localised changes
- Isolating bugs is more challenging
- Cannot test individual components
- Cannot reuse code
I would advise Sam to consider the example of initialising the model weights. While my initialise_random_tensor might have a near-identical implementation to his, I have extended it to support any arbitrary dimensionality and have encapsulated the numpy implementation details. This means that initialise_random_tensor could be used in any other model that needs to randomly initialise a tensor and the numpy implementation could, for example, be swapped out with another implementation such as jax.numpy for GPU acceleration, without having to manually update each of those functions.
Typing and comments
Code should tell a story to the reader and be as clear and simple as possible to follow. I would suggest to Sam that he would have better control over the story he is trying to tell if he used type hinting and comments. However, these should only be used if they add signal to the code. Commenting # Add numbers A and B above return sum(A, B) does not add any signal - it dilutes the current signal.
Let's consider my function:
Node = namedtuple("Node", ['i', 'j'])
def _find_best_matching_unit(weights: NDArray[np.float32], x: NDArray[np.float32],
width: int, height: int) -> Node:
"""Finds the network node that is currently most similar to `x`."""
bmu = np.argmin(jnp.sum((weights - x) ** 2, axis=2))
return Node(*jnp.unravel_index(bmu, (height, width)))
By abstracting this implementation into a helper function, I get the same modularisation benefits as discussed above because someone following a story that uses _find_best_matching_unit only needs to understand what it does to continue the story, not how it does what it does. I have done a few things to communicate what this function does as concisely as possible.
- Including argument type hints provides important context for the reader/user to ascertain what the author expects the function to operate on.
- Declaring a named tuple return type,
Node, informs the reader what the function returns and is more descriptive than simplyTuple[int, int]. - Adding a docstring that phrases the function's logic in natural language can aid in the reader's understanding without needing to read its implementation.
Performance
Sam's implementation could benefit considerbaly from some vectorised operations instead of iterating over each node and updating its weight. Vectorised operations in numpy are implemented to leverage highly efficient, low-level code that can utilise hardware acceleration - often resulting in large speed-ups.
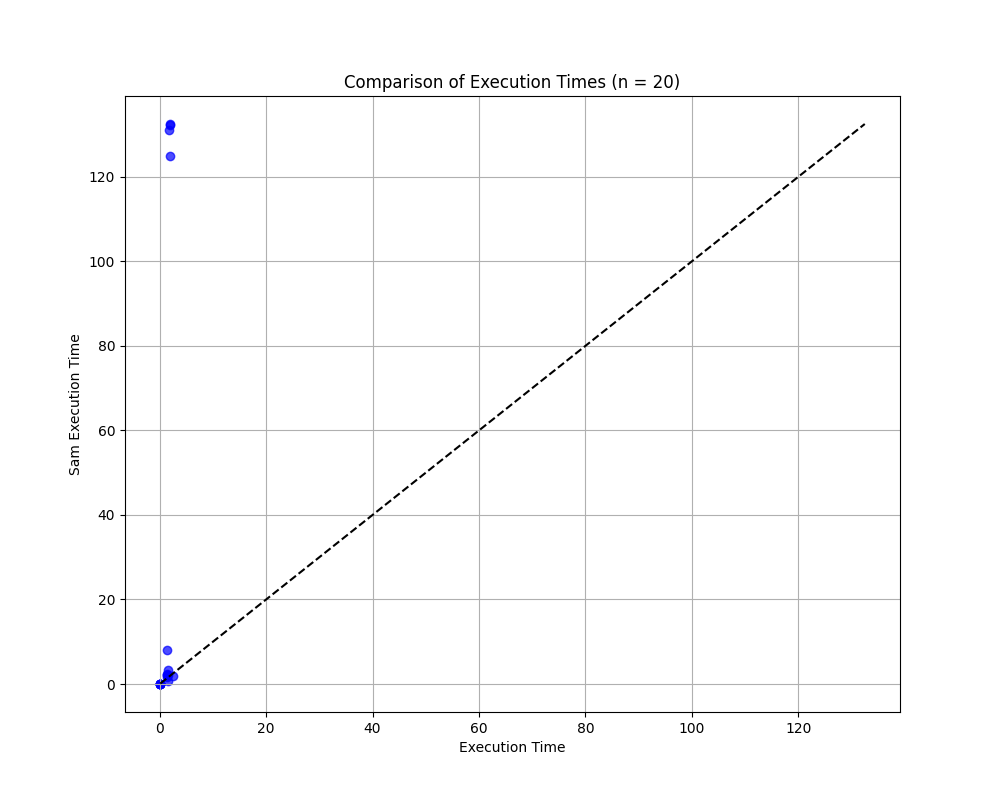
In my implementation, I abstracted out _update_weights so that I could wrap it in JAX Just-In-Time compilation to compile the function using XLA (Accelerated Linear Algebra.) The below image shows the output of a benchmark comparing my implementation to Sam's implementation for random parameters and inputs. In this benchmark, JAX was configured to use my CPU - one could configure the module to use JAX on a GPU for even greater speed gains. While JAX does add some overhead and may be less efficient for very simple networks, it is orders of magnitude faster for complex networks.
Testing
As part of productionising this application, it is critical to rigorously test the implementation so that any bugs are and issues are identified before launching to production, any bugs are picked up after making changes post launching to production and writing tests often highlights code-smells - encouraging better software development practices.
I have used pytest to write unit and integration tests. In addition, I have used the Hypothesis library to employ property-based testing. Let's consider the below example:
@given(
X=st.one_of(
st.lists(st.floats(allow_nan=False, allow_infinity=False, min_value=-1e6, max_value=1e6)), # Not 2D
st.just(np.array([])) # Empty
),
width=st.integers(max_value=MINIMUM_NETWORK_DIMENSION - 1), # Includes non-positive
height=st.integers(max_value=MINIMUM_NETWORK_DIMENSION - 1), # Includes non-positive
num_iterations=st.integers(max_value=0), # Includes non-positive
initial_learning_rate=st.one_of(
st.floats(max_value=0.0, allow_nan=False, allow_infinity=False), # Includes non-positive and NaN/inf
)
)
def test_create_kohonen_params_invalid_failure(X, width, height, num_iterations, initial_learning_rate):
result = create_kohonen_params(X, width, height, num_iterations, initial_learning_rate)
assert isinstance(result, Failure) and isinstance(result.failure(), ValueError)
Rather than trying to think of differnt edge cases, hypothesis will simulate many different inputs that we expect to break the create_kohonen_params function. Importantly, hypothesis will try and break our test, i.e. find inputs that do not result in a Failure return type from create_kohonen_params, and it will then find the minimum failing example so the set of parameters that broke the test is as obvious as possible. If this test passes, I can be confident that create_kohonen_params is correctly returning a ValueError failure whenever it receives invalid inputs (e.g. negative width.)
The concept of a Result return type from a function is implemented by the Returns library and is a functional nomad declaring that as a Result, it will either have a value if the function succeeded, or one of a defined set of exceptions if it failed. This enforces deliberate and explicit exception-handling/propagation. In the above example, we declare explicitly that create_kohonen_params should return a ValueError if it receives any invalid input.
Benchmarking
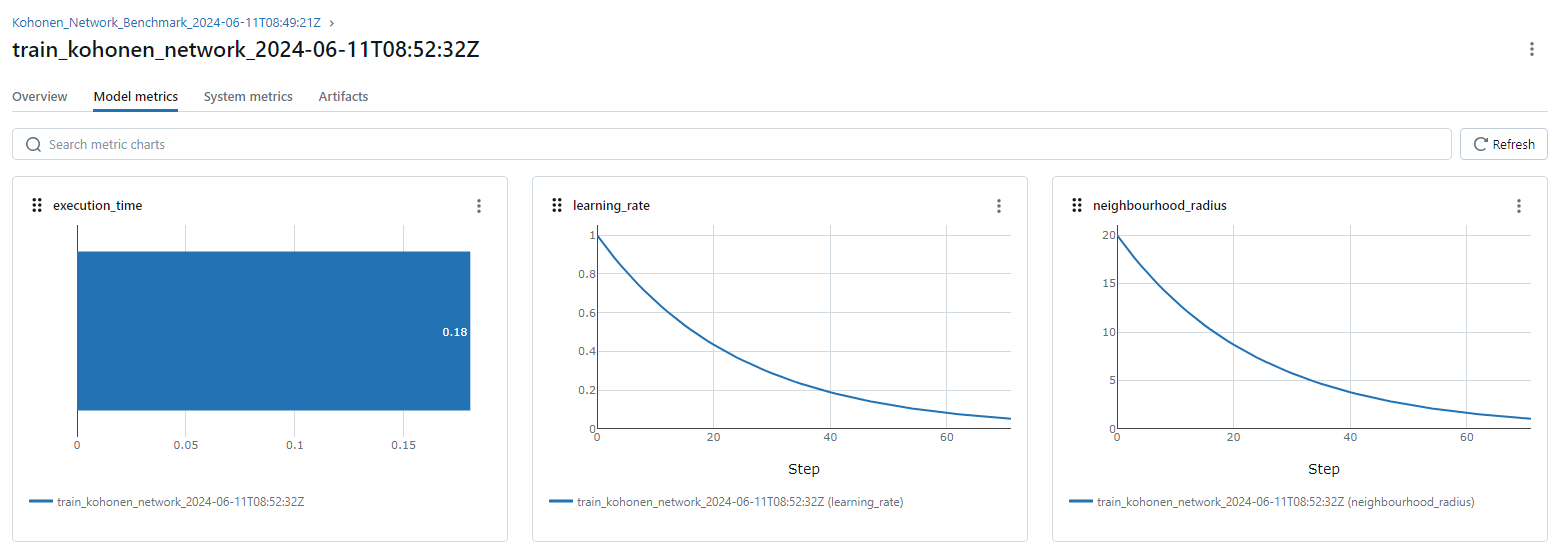
I also used hypothesis to simulate different scenarios and thus evaluate the performance of both my implementation and Sam's. To assist in the benchmarking, I used MLFlow to allow me to visually compare the models and inspect different metrics. Another benefit of MLFlow is the ability to inspect metrics across iterations. For example, in the below image, we can see that both neighbourhood radius and learning rate reduce exponentially. This is a solid sanity check. Using a tool such as MLFlow makes comparing experiments and collaborating on models far easier. My inclusion of MLFlow in this codebase is pretty barebones and does not have any secret injection. I would encourage Sam to use MLFlow early into model development so he can measure and quantify how different model implementations and versions perform.
Deployment
Since one of the primary benefits of the Kohonen Map is to perform dimensionality reduction, it is possible that all that need be deployed is the models package. One would likely want to name the package more descriptive, such as kohonen_network. It would be straightforward to use GitHub Actions to automatically update the package and submit it to a PyPi repository, allowing people to use train_kohon_network and perform dimensionality reduction in their own pipelines.
Alternatively, the package could be imported into a Python Flask application that is hosted in a Docker container in a Kubernetes cluster or on a bare-metal server. This would make for an endpoint that any other services could use. Rather than a self-managed Flask app, one could use Databricks to solve the model, which has the added benefit of natively fitting into Databricks pipelines.
A few example use-cases (beyond dimensionality reduction as a data preprocessing step) are:
- Image Processing. Kohonen Networks can cluster similar colors in an image for use in image compression, reducing the color palette to essential colors while maintaining visual fidelity.
- Detecting Abnormal Behavior in Industrial Systems. Kohonen Networks can monitor data streams from sensors in industrial settings, such as temperature or pressure readings, to detect deviations from standard operating conditions that may indicate equipment malfunctions or safety hazards.
- Market Segmentation. Kohonen networks can be used to cluster customers based on purchasing behavior and preferences, helping businesses tailor marketing strategies.